








- 课程概览
- 授课讲师
- 课程大纲
- 课程概览
- 授课讲师
- 课程大纲
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,就能把网页上的信息提取出来。那么通过本课程我们将会学习如何编写爬虫程序,从而能够在网络上爬取自己想要的一些数据或图片视频
 课程概览
课程概览
本课程旨在帮助学员了解网络爬虫的基本概念、原理和常用工具,掌握数据采集的技术和方法。通过本课程的学习,学员将能够使用Python语言开发简单的网络爬虫,从静态网页和动态网页中获取数据,并对数据进行处理和分析。
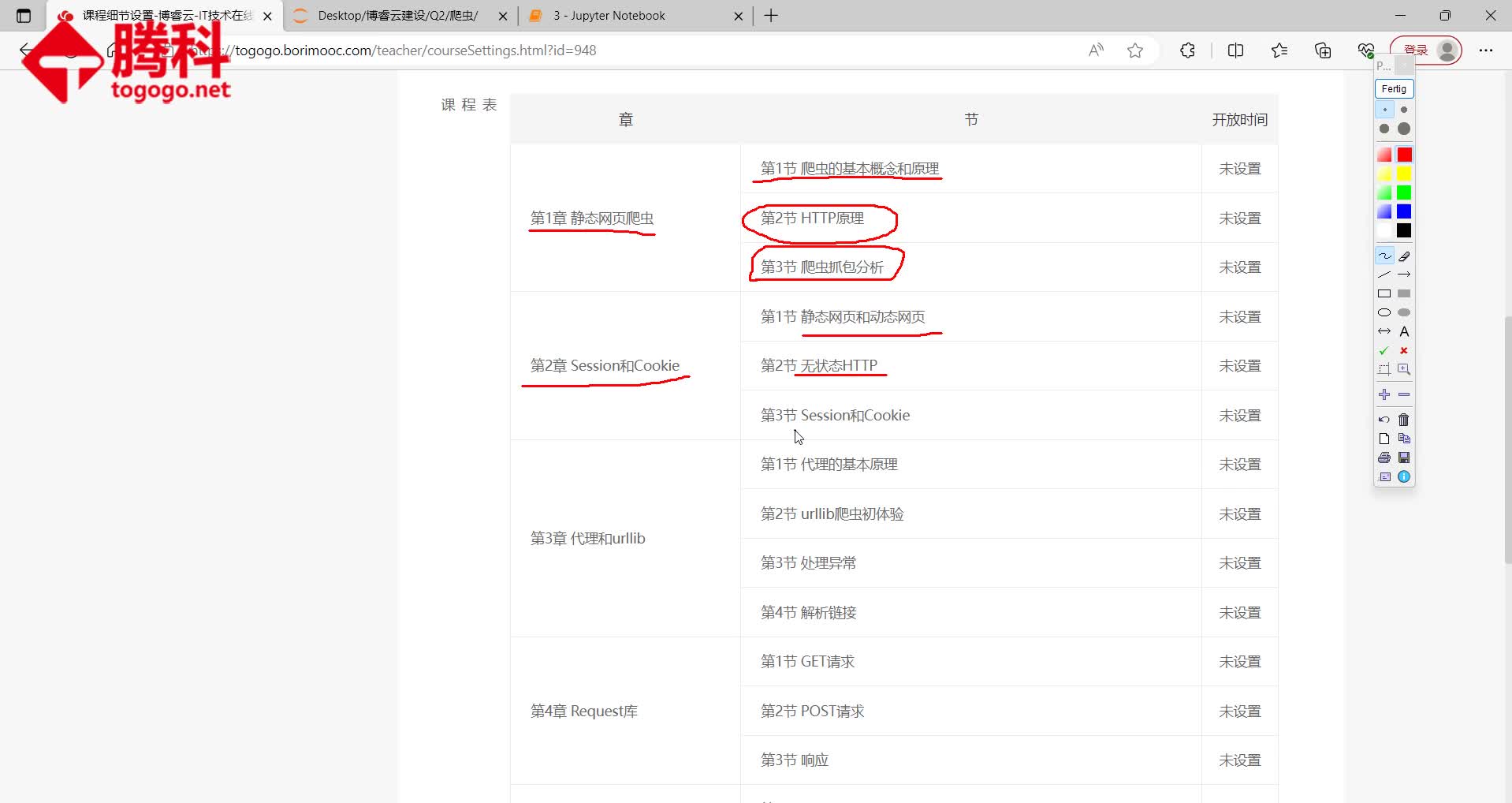
第1章 静态网页爬虫
-
第1节 爬虫的基本概念和原理
- 爬虫的定义和作用
- 爬虫的工作原理和基本流程
- Robots.txt协议的理解和遵守
-
第2节 HTTP原理
- HTTP请求和响应的结构
- HTTP请求方法的分类和用途
- HTTP状态码及其含义
-
第3节 爬虫抓包分析
- 使用抓包工具进行网络数据的捕获和分析
- 分析HTTP请求和响应,提取关键信息
第2章 Session和Cookie
-
第1节 静态网页和动态网页
- 静态网页和动态网页的区别
- 动态网页的生成原理和数据加载方式
-
第2节 无状态HTTP
- HTTP协议的无状态特性
- Session和Cookie的引入和作用
-
第3节 Session和Cookie
- Session的工作原理和实现
- Cookie的原理和用途
- 使用Session和Cookie处理登录和用户状态
第3章 代理和urllib
-
第1节 代理的基本原理
- 代理服务器的作用和分类
- 使用代理IP隐藏真实身份
-
第2节 urllib爬虫初体验
- Python的urllib库简介
- 使用urllib发送HTTP请求获取页面数据
-
第3节 处理异常
- 处理网络请求中的异常情况
- 设置超时和重试机制
-
第4节 解析链接
- 提取页面中的链接信息
- 相对链接和绝对链接的处理
第4章 Request库
-
第1节 GET请求
- 使用Request库发送GET请求获取数据
- 添加请求头和查询参数
-
第2节 POST请求
- 使用Request库发送POST请求提交数据
- 处理表单数据和JSON数据
-
第3节 响应
- 解析HTTP响应数据
- 获取响应状态、头部和内容
第5章 正则表达式
-
第1节 实例引入
- 正则表达式的作用和基本概念
- 使用正则表达式进行数据匹配
-
第2节 匹配方法
- 常用的正则表达式匹配方法
- 使用捕获组提取数据
第6章 BeautifulSoup
-
第1节 BeautifulSoup简介
- BeautifulSoup库的作用和特点
- 安装和基本用法
-
第2节 BeautifulSoup四大对象
- Tag、NavigableString、BeautifulSoup和Comment的使用
- 对象的属性和方法
-
第3节 遍历文档树
- 遍历和搜索文档树的方法
- 提取数据和节点信息
-
第4节 搜索文档树
- 使用标签名、CSS类、属性等条件进行节点搜索
- find和find_all方法的使用
-
第5节 CSS选择器
- 使用CSS选择器快速定位元素
- 选择器的语法和常见用法
第7章 XPath
-
第1节 基本术语
- XPath的定义和作用
- 节点、路径、谓语等基本术语
-
第2节 基本语法
- XPath表达式的写法和规则
- 使用XPath提取数据
第8章 Scrapy爬虫
-
第1节 Scrapy爬虫概述
- Scrapy框架的特点和优势
- Scrapy的安装和项目创建
-
第2节 Scrapy体系架构和数据流
- Scrapy框架的组成和工作流程
- 数据在Scrapy中的传递和处理
-
第3节 Scrapy爬虫项目
- 编写一个简单的Scrapy爬虫
- 爬取数据并进行持久化处理

 课程大纲
课程大纲
- 第1章静态网页爬虫
- 第1节爬虫的基本概念和原理
- 第2节HTTP原理
- 第3节爬虫抓包分析
- 第2章Session和Cookie
- 第1节静态网页和动态网页
- 第2节无状态HTTP
- 第3节Session和Cookie
- 第3章代理和urllib
- 第1节代理的基本原理
- 第2节urllib爬虫初体验
- 第3节处理异常
- 第4节解析链接
- 第4章Request库
- 第1节GET请求
- 第2节POST请求
- 第3节响应
- 第5章正则表达式
- 第1节实例引入
- 第2节匹配方法
- 第6章BeautifulSoup
- 第1节BeautifulSoup四大对象
- 第2节遍历文档树
- 第3节搜索文档树
- 第4节CSS选择器
- 第7章XPath
- 第1节基本术语
- 第2节基本语法
| 节数 | 上课时间 | 星期一 | 星期二 | 星期三 | 星期四 | 星期五 | 星期六 | 星期天 |
|---|---|---|---|---|---|---|---|---|
| 第1节 | 08:00 - 08:40 | |||||||
| 第2节 | 09:00 - 09:40 | |||||||
| 第3节 | 10:00 - 10:40 | |||||||
| 第4节 | 11:00 - 11:40 | |||||||
| 第5节 | 14:00 - 14:40 | |||||||
| 第6节 | 15:00 - 15:40 | |||||||
| 第7节 | 16:00 - 16:40 | |||||||
| 第8节 | 17:00 - 17:40 |
| 天数 | 上课日期 | 上课时间 | 内容 |
|---|
相关课件 更多
-

pdf
第6章 BeautifulSoup
大小:819.34KB
2024-11-25
-

pptx
第7章 XPath的使用
大小:373.04KB
2024-11-25
-
pptx
第5章 正则表达式
大小:717.59KB
2024-11-25
-
pptx
第4章 Requests库
大小:389.8KB
2024-11-25
-
pptx
第3章 代理和urllib(2)
大小:837.38KB
2024-11-25
-
pptx
第3章 代理 和 urllib
大小:687.24KB
2024-11-25


 020-38289118 转 171
020-38289118 转 171